
本文目的
鉴于目前网络上并无相关从 imagenet 官网下载竞赛数据到训练的相关教程,本文提供从获取数据到训练的全步骤讲解。
下载并解压数据
-
进入官网下载页面 https://image-net.org/challenges/LSVRC/2012/2012-downloads.php 获取下载链接。
-
利用
wget命令下载数据(一共四个数据文件)。1
2
3
4wget https://image-net.org/data/ILSVRC/2012/ILSVRC2012_img_train.tar
wget https://image-net.org/data/ILSVRC/2012/ILSVRC2012_img_val.tar
wget https://image-net.org/data/ILSVRC/2012/ILSVRC2012_img_train_t3.tar
wget https://image-net.org/data/ILSVRC/2012/ILSVRC2012_img_test_v10102019.tar -
利用
tar命令解压缩数据包放入指定文件夹首先尝试解压缩部分文件探索数据文件目录结构:
tar -xvf ./ILSVRC2012_img_train_t3.tar -C test。然后,通过bash命令批处理删除生成的文件:find ./test -name '*.JPEG' -type f -print -exec rm -rf {} \;。经探索发现文件结构如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22| - - ILSVRC2012_img_train.tar
| - - n01440764.tar
| - - n01440764_2708.JPEG
| - - n01440764_7173.JPEG
···
···
| - - ILSVRC2012_img_val.tar
| - - ILSVRC2012_val_00010062.JPEG
| - - ILSVRC2012_val_00009546.JPEG
...
| - - ILSVRC2012_img_train_t3.tar
| - - n02085620.tar
| - - n02085620_10074.JPEG
| - - n02085620_10131.JPEG
···
···
| - - ILSVRC2012_img_test_v10102019.tar
| - - test
| - - ILSVRC2012_test_00013640.JPEG
| - - ILSVRC2012_test_00020698.JPEG
···
... -
编写
python脚本文件批处理解压并删除中间tar文件:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33import tarfile
import os
from tqdm import tqdm
def get_tar(path):
tar_files = []
for name in os.listdir(path): # 遍历当前目录下所有文件和文件夹
if '.tar' in name: # 筛选出当前文件夹下需要解压的 .tar 文件
tar_files.append(name)
return tar_files
def untar(ori_file):
print("Untar the file: " + ori_file)
new_dir_name = os.path.splitext(ori_file)[0]
tar = tarfile.open(ori_file)
names = tar.getnames()
for name in tqdm(names):
tar.extract(name, new_dir_name)
if '.tar' in name:
new_ori_file = os.path.join(new_dir_name, name) # 获取 tar 包内的 tar 包文件
untar(new_ori_file) # 解压 tar 包
os.remove(new_ori_file) # 解压完成后删除 tar 包
tar.close()
def main():
abs_path = os.getcwd() # 获取当前文件所在目录绝对路径
tar_files = get_tar(abs_path) # 获取待解压的所有 tar 包
for tar_file in tar_files:
ori_file = os.path.join(abs_path, tar_file)
untar(ori_file)
if __name__ == "__main__":
main() -
上述代码保证了解压缩完的数据文件与原始的
tar包文件结构一致(去除.tar后缀直接做文件夹名称)。
获取标签
-
从官网下载 Development Kit,获取1000个分类类别标签。
两个压缩包解压后的目录结构如下所示:
1
2
3
4
5
6
7
8
9| - - ILSVRC2012_devkit_t12
| - - COPYING
| - - data
| - - ILSVRC2012_validation_ground_truth.txt
| - - meta.mat
| - - evaluation
| - - *.txt
| - - *.m
| - - readme.txt其中,true label 的 value 存储于
ILSVRC2012_devkit_t12/data/文件夹下。其中.txt文件包含 50,000 验证集的 class index values,每一行为对应图片(images 按序编号)的 class index label。另外,其余训练集信息包含于
meta.mat文件中,用 matlab 打开该文件,其中大小为的 synsets 结构体包含的数据详情如下截图所示: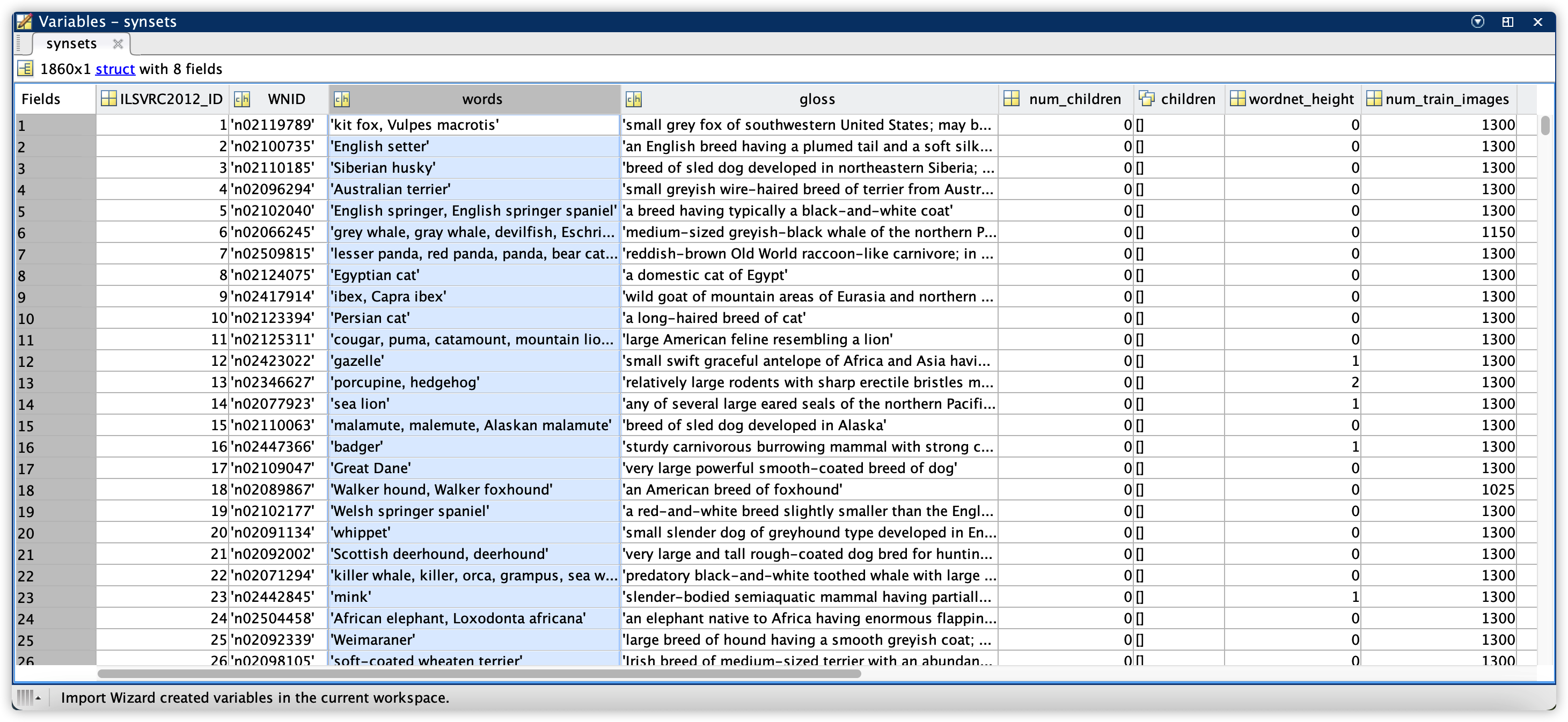
其中关键信息为 ILSVRC2012_ID 和 WNID 两列,分别对应 class true label 和训练集文件夹名称。
-
数据集与标签匹配关系(借用 Cheat Sheet of Counting Files or Folders 探索解压后文件夹结构)
训练集
ILSVRC2012_img_train下一级目录名(#1000)均可在 synsets 结构体 WNID 列(#1860)内找到对应,从而可以锁定以 WNID 为目录名下所有图片标签。验证集
ILSVRC2012_img_val下直接存储验证集所有图片(#50000),其文件名为ILSVRC2012_val_00000001到ILSVRC2012_val_00050000。这时我们需要借助ILSVRC2012_devkit_t12/data/ILSVRC2012_validation_ground_truth.txt文件来匹配文件名所对应的 ILSVRC2012_ID,从而在 synsets 结构体中与 WNID 关联。测试集(#100000)同验证集
综上所述,训练集通过
目录名称 -> synsets -> WNID -> ILSVRC2012_ID匹配上标签,验证集和测试集通过文件名 -> ILSVRC2012_validation_ground_truth.txt -> synsets -> ILSVRC2012_ID -> WNID匹配上标签。
数据集整理
-
训练集目录结构刚好符合
torchvision.datasets.ImageFolder的目录结构安排。以此为标准,我做了如下的整理:
- 训练集结构不变,次级目录名称由 WNID 改为 ILSVRC2012_ID
- 验证集与测试集按照训练集标准安排结构,类别序号(ILSVRC2012_ID)做目录名称,包含该类别所有图片
-
编写
python脚本按照上述思路整理数据集:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38import os
import shutil
import scipy.io as sio
def rename_train(meta_data, img_root):
dir_names = os.listdir(img_root)
for dir_name in dir_names:
for item in meta_data:
if dir_name == item[0][1][0]:
os.rename(os.path.join(img_root, dir_name), os.path.join(img_root, str(item[0][0][0][0])))
break
def group_val(ground_truth, img_dir):
with open(ground_truth) as f:
lines = f.readlines()
labels = [int(line.strip()) for line in lines]
filenames = os.listdir(img_dir)
for filename in filenames:
img_idx = int(filename.split('_')[-1].split('.')[0])
ILSVRC_ID = labels[img_idx - 1]
output_dir = os.path.join(img_dir, str(ILSVRC_ID))
if not os.path.isdir(output_dir):
os.mkdir(output_dir)
shutil.move(os.path.join(img_dir, filename), os.path.join(output_dir, filename))
pass
if __name__ == "__main__":
synsets = '/data/Datasets/ImageNet2012/ILSVRC2012_devkit_t12/ILSVRC2012_devkit_t12/data/meta.mat'
ground_truth = '/data/Datasets/ImageNet2012/ILSVRC2012_devkit_t12/ILSVRC2012_devkit_t12/data/ILSVRC2012_validation_ground_truth.txt'
val_dir = '/data/Datasets/ImageNet2012/ILSVRC2012_img_val'
train_dir = '/data/Datasets/ImageNet2012/ILSVRC2012_img_train'
meta_data = sio.loadmat(synsets)["synsets"]
a = meta_data[0, 0][1][0]
rename_train(meta_data, train_dir)
group_val(ground_truth, val_dir)其中
rename_val用于训练集分类别目录重命名,group_val用于验证集图片整理。 -
整理完的训练集与验证集目录结构如下(同
torchvision.datasets.ImageFolder):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19| - - ImageNet2012
| - - ILSVRC2012_img_train
| - - 1
| - - n02119789_10007.JPEG
| - - n02119789_10584.JPEG
| - - n02119789_11491.JPEG
...
| - - 2
...
...
| - - ILSVRC2012_img_val
| - - 1
| - - ILSVRC2012_val_00000756.JPEG
| - - ILSVRC2012_val_00006145.JPEG
| - - ILSVRC2012_val_00009128.JPEG
...
| - - 2
...
... -
根据统计,训练集共有 1,281,167 张图片+标签,验证集有 50,000 张图片+标签,测试集有 100,000 张图片,和官方标准一样。
写在最后
本文目的在于探索一个未知数据集的具体解决思路,从python脚本语言入手简洁明了。为了更加高效,可直接移步pytorch官方bash处理方法
Reference
[2] ILSVRC2012 Official Website
[2] ImageNet数据集到底长什么样子? - 七个太阳的回答 - 知乎
[3] ImageNet使用方法? - 薰风初入弦的回答 - 知乎

